Incorporating Defender’s Behaviour in Autonomous Pen-Testing
Penetration testing (pen-testing) is one of the most effective methods for assessing the security of a computer network. It identifies vulnerabilities by emulating a real attack. However, pen-testing is costly, rendering it unaffordable to many. As such, there is a growing need for the development of autonomous approaches to pen-testing.
A key component in pen-testing is deciding what part of the network to target, which tool to use, and in what sequence. The challenge is the pen-tester does not have knowledge of the network or hosts, e.g. what services each host is running, or any passwords, or what traffic is blocked by the firewall. Additionally, some exploits may be unreliable and require more effort or time to work. Lastly, the network administrator (defender) may actively try to prevent any attack by doing things such as restarting machines, removing any fishy programs or blocking traffic via the firewall. For these reasons, autonomous pen-testing is a planning under uncertainty problem, where uncertainty is caused by (i) partial observability of the network properties and its vulnerabilities, (ii) unreliability of the attack tools, and (iii) the possible changes to the system due to the defender. This project aims to develop autonomous pen-testers that account for all of these three types of uncertainty.
Due to the partially observed nature of the problem, the Partially Observable Markov Decision Process (POMDP) is a suitable approach for autonomous pen-testing. In fact, Sarruate, et.al. has shown POMDP is an effective approach for autonomous pen-testing that needs to handle the first two sources of uncertainty: Partial observability and unreliable actions. However, incorporating the defender's behaviour remains an open problem because, it requires a model of the defender's strategy, which depends on the attacker's strategy, which in turn depends on the defender's strategy, and this back and forth dependencies continues, causing an explosion in the number of state variables of the POMDP model.
In this project, we developed a POMDP-based autonomous pen-tester, called D-PenTesting, that can efficiently account for the defender's behaviour without increasing the size of the POMDP problem, thereby enabling autonomous pen-testing to account for all three types of uncertainty mentioned above. Key to D-PenTesting is both pen-tester and defender can only interact via the computer network, and therefore, the defender's behaviour can be simplified and modelled as a Markov Arrival Process that reflects the changes in the properties of the network. Taking the simplest of such a process, we abstracted the defender’s actions into two types: Network analysis, which does not alter the network, and active defence operations, which alter the network. This abstraction enables us to represent the defender’s behaviour as a single variable: An information decay factor, which can be encoded in the dynamics model of the POMDP agent, so as to prevent increasing the size of the POMDP model. Information decay variable reflects the expected time the defender takes to move from analysing to actively defending the network. Experimental results indicate that with suitable decay factor, D-PenTesting is effective against different defender strategies.
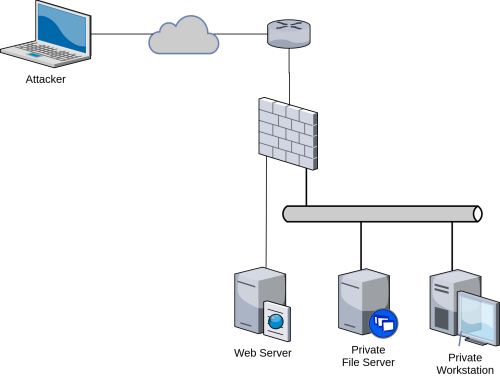
Experimental results of applying D-PenTesting. Left: The scenario. Right: The results of running D-PenTesting on the scenario depicted on the left figure. The different plots indicate the performance of D-PenTesting against different strategies of the defender. Decay factor 0 is equivalent to POMDP-based pen-tester that does not take into account the defender's behaviour.
Obviously, different defenders have different speed in moving from analysis to active defence mechanism. And the question becomes how would D-PenTesting find a suitable decay factor, while it does not know the strategy of the defender. To alleviate this difficulty, we propose a Bayesian Reinforcement Learning based pen-tester, called LD-PenTesting. LD-PenTesting learns the suitable decay factor (which implicitly means learning the defender's behaviour) as it decides how to attack the network via Bayesian Reinforcement Learning approach cast as yet another POMDP. Experimental results indicate that although LD-PenTesting does not know a suitable decay factor, its performance is close to D-PenTesting with the correct decay-factor. An example of these results is shown below.
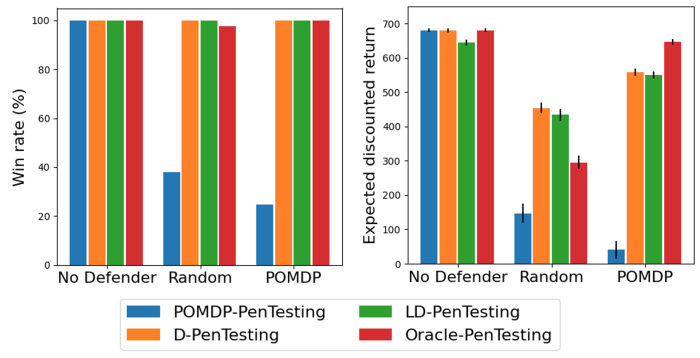
Performance comparison of LD-PenTesting and other pen-testing methods over 1,000 runs. The labels on the X-axis reflects the defender's strategy. POMDP-PenTesting refers to POMDP-based pen-testing that does not take the defender's behaviour into account. D-PenTesting refers to D-PenTesting with the most suitable decay-factor, based on preliminary experiments. Oracle-PenTesting refers to a POMDP-based pen-testing that knows the exact next action of the defender, and is introduced as an upper bound comparison.
Details of the methods and experimantal results are available in the references below:
References
People
- Jonathon Schwartz
- Hanna Kurniawati
- Edwin El-Mahassni